JPA 1차 캐시와 2차 캐시에 관해서는 이 글을 읽기 전에 한 번 읽어보시길 추천드립니다.
클라이언트의 요청에 의해 영속성 컨텍스트의 스냅샷을 통한 1차 캐시는 그 생명주기가 OSIV인 경우 요청이 끝날 경우에 사라집니다.(OSIV가 아닌 경우 트랜잭션이 종료되면 영속성 컨텍스트가 종료될 때 같이 사라집니다.)
그렇다면 매번 반복된 요청이 들어올 때 불필요한 디비 컨넥션 처리가 이루어지지 않도록 2차 캐시를 이용하여 효율성을 높이는 것이 좋다고 생각이 됩니다.
2차 캐시를 적용해서 한번 로직을 구성해 보겠습니다.
@Override
public List<DSong> findByTop100Song() {
return jpaQueryFactory.selectFrom(song)
.where(song.isDeleted.eq(false))
.orderBy(song.heart.desc())
.limit(100)
.setHint("org.hibernate.cacheable", true)
.setHint("jakarta.persistence.cache.retrieveMode", CacheRetrieveMode.USE)
.setHint("jakarta.persistence.cache.storeMode", CacheStoreMode.USE)
.fetch()
.stream().map(DSong::from).toList();
}
위의 코드는 좋아요를 기준으로 탑 100곡을 가져오는 queryDsl의 메서드입니다.
여기서는 jakarta.persistence.cache.retrieveMode, storeMode를 사용해서 2차 캐시를 적용했습니다.
yaml에 spring.jpa.properties.hibernate.generate_statistics = true로 설정을 해놓으면 다음과 같이 로그를 통해 캐시에 적재됐을 때와 캐시 히트했을 때를 확인할 수 있습니다.
캐시 미스로 쿼리를 통해 데이터를 캐싱처리할 때 로그입니다.

JDBC executing time: 23,603,100 ns
L2C putting time: 98,210,500 ns
총 소요 시간: 121,813,600 ns => 약 0.121 s
캐시 히트로 쿼리를 실행하지 않고 결과를 반환할 때 로그입니다.
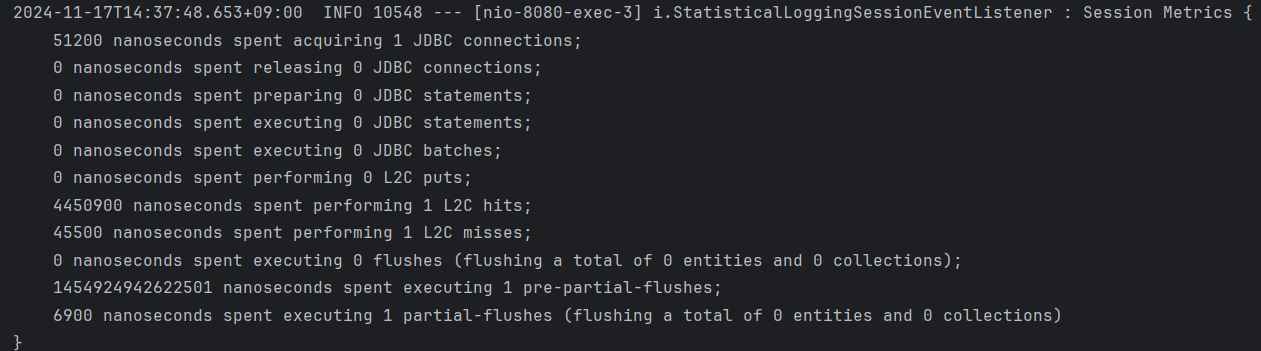
L2C hits time: 4,450,900 ns
L2C misses time: 45,500 ns
총 소요 시간: 4,496,400 ns => 약 0.004s
결과적으로 96.69% 성능 개선이 됐다고 볼 수 있습니다.
여기서 주목할만한 점은 JPA 2차 캐시는 엔티티 단위로 캐싱된다는 점입니다.
JPA 책의 저자 김영한님은 다음과 같은 언급을 하셨습니다.
주의해야할 점은 엔티티를 스프링이나 외부 캐시에 저장하면 절대! 안됩니다.
엔티티는 영속성 컨텍스트에서 상태를 관리하기 때문에, 항상 DTO로 변환해서 변환한 DTO를 캐시에 저장해서 관리해야 합니다!
캐시와 관련해서 제가 실무 조언을 드리고 싶은 부분은 하이버네이트 2차 캐시보다는 스프링이 지원하는 캐시를 서비스 계층에서 사용하는게 더 효과적이라는 점 입니다. 2차 캐시는 설정도 복잡하고, 지원하는 캐시 라이브러리도 작습니다. 무엇보다 실무에서는 서비스 계층에서 복잡하게 외부 API도 호출하고, 여러 엔티티도 조회해서 그 결과로 DTO를 생성합니다. 스프링을 사용하면 이 DTO를 효과적으로 캐시할 수 있고, 지원하는 캐시 라이브러리도 풍부합니다. 그런데 2차 캐시는 단순히 엔티티 조회(쿼리포함)와 관련된 부분만 캐시가 지원됩니다.
위의 조언을 참고하여 JPA 2차 캐시를 적용하지 않고 스프링 캐시를 적용하는 것이 더 좋다는 판단했습니다.
스프링 캐시 적용하기
스프링 캐시에는 EhCache, Caffeine, Redis 캐시가 대표적으로 보이는데,
저는 여러 서버 인스턴스가 동시에 같은 캐시 데이터를 바라봐야 한다는 것을 전제로 해서 레디스 캐시를 선택했습니다.
우선 의존성을 추가합니다.
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
yaml 파일을 수정합니다.
spring:
cache:
type: redis
redis:
host: localhost
port: 6379
jedis:
pool:
max-active: 10
max-idle: 5
min-idle: 1
max-wait: 2000
Spring에서 Redis를 캐시 관리자로 사용할 수 있도록 RedisCacheManager를 설정합니다.
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager(RedisConnectionFactory redisConnectionFactory){
// Redis 캐시 설정
RedisCacheConfiguration cacheConfig = RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())
)
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new Jackson2JsonRedisSerializer<>(Object.class)
)
)
.entryTtl(Duration.ofMinutes(10)); // 기본 TTL 10분
return RedisCacheManager.builder(
RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory)
)
.cacheDefaults(cacheConfig)
.build();
}
}
이제 캐싱을 적용해보려고 합니다.
캐시를 적용하려는 서비스 메서드에 @Cacheable, @CachePut, @CacheEvict 등의 애너테이션을 사용합니다.
- @Cacheable: 캐시 조회 및 저장을 담당합니다. 해당 메서드가 호출되기 전에 캐시를 먼저 조회하고, 캐시에 데이터가 없을 경우 메서드를 실행하여 반환값을 캐시에 저장합니다.
- @CachePut: 메서드가 항상 실행되며, 실행 결과를 캐시에 저장합니다. 캐시를 갱신할 때 사용됩니다.
- @CacheEvict: 캐시 데이터를 삭제할 때 사용되며, 메서드 실행 전후에 캐시 데이터를 제거할 수 있습니다.
@Transactional(readOnly = true)
@Cacheable(value = "getTop100")
public List<SongResponse> getTop100(){
return songRepository.findByTop100Song()
.stream().map(SongResponse::from).toList();
}
value를 통해 캐시 이름을 지정할 수 있습니다.
Logging Level을 TRACE로 설정한 후 결과를 확인해 보겠습니다.
logging:
level:
org.springframework.cache: TRACE
캐시가 없을 때는 아래와 같은 로그가 보여지며 데이터베이스 쿼리를 수행한 후 캐시를 생성합니다.
o.s.cache.interceptor.CacheInterceptor : Computed cache key 'SimpleKey []' for operation Builder[public java.util.List com.board.application.service.SongService.getTop100()] caches=[getTop100] | key='' | keyGenerator='' | cacheManager='' | cacheResolver='' | condition='' | unless='' | sync='false'
o.s.cache.interceptor.CacheInterceptor : No cache entry for key 'SimpleKey []' in cache(s) [getTop100]
... select query log ...
o.s.cache.interceptor.CacheInterceptor : Creating cache entry for key 'SimpleKey []' in cache(s) [getTop100]
소요 시간: 931ms
캐시 히트가 됐을 때는 다음과 같은 로그가 보여집니다.
o.s.cache.interceptor.CacheInterceptor : Computed cache key 'SimpleKey []' for operation Builder[public java.util.List com.board.application.service.SongService.getTop100()] caches=[getTop100] | key='' | keyGenerator='' | cacheManager='' | cacheResolver='' | condition='' | unless='' | sync='false'
o.s.cache.interceptor.CacheInterceptor : Cache entry for key 'SimpleKey []' found in cache(s) [getTop100]
소요 시간: 27ms
성능 개선은 97.09% 개선됐습니다.
궁금증
- 캐시에 TTL을 개별적으로 등록하는 방법은 없을까?
- 공유 캐시와 원격 캐시의 차이점은 무엇일까?
'[개발] 프레임워크 > JPA' 카테고리의 다른 글
| [JdbcTemplate] batchUpdate 를 통해 bulk insert를 하는 방법 (1) | 2024.12.07 |
|---|---|
| [JPA] @BatchSize와 쿼리 캐시에 관해서 알아보기 (1) | 2024.11.28 |
| JPA 1차 캐시와 2차 캐시 (1) | 2024.11.12 |
| 낙관적 락과 비관적 락 (2) | 2024.11.03 |
| QueryDSL에 대해서 알아보자. (4) | 2024.10.20 |


