티스토리 뷰
책 소개
Devsong26
2024. 6. 22. 07:00
도메인
- 소프트웨어로 해결하고자 하는 문제 영역
- 도메인은 하위 도메인으로 나눌 수 있음
도메인 모델 패턴
- 일반적인 애플리케이션의 아키텍처는 네 개의 영역으로 구성

- 표현 영역(Presentation): 사용자(혹은 외부 시스템)의 요청을 처리하고 사용자에게 정보를 보여줌
- 응용 영역(Application): 사용자가 요청한 기능을 실행하며 업무 로직을 직접 구현하지 않고 도메인 계층을 조합해서 기능을 수행
- 도메인(Domain): 시스템이 제공할 도메인 규칙을 구현
- 도메인의 핵심 규칙을 구현
- 도메인 규칙을 객체 지향 기법으로 구현하는 패턴이 도메인 모델 패턴
- 인프라스트럭처(Infrastructure): 데이터베이스나 메시징 시스템과 같은 외부 시스템과의 연동을 처리
엔티티와 밸류
- 도출한 모델은 크게 엔티티와 밸류로 구분
- 엔티티의 가장 큰 특징은 식별자를 가진다는 것
- 밸류 타입은 개념적으로 완전한 하나를 표현할 때 사용
- 예시: address1, address2, zipcode 는 Address라는 밸류 타입으로 선언 가능
- 밸류 타입은 기능을 추가할 수 있음
- 밸류 타입은 안전한 코드를 작성하기 위해 불변 객체로 만들어야 함
- 도메인 객체가 불완전한 상태로 사용된 것을 막기 위해 생성자를 통해 필요한 데이터를 모두 받아야 함
- 엔티티는 DB 테이블의 엔티티와 다르게 데이터와 함께 기능을 제공
- 도메인 모델의 엔티티는 밸류 타입으로 표현이 가능
- 엔티티의 밸류는 불변이라 변경하려면 객체를 교체해야 함
표현 영역

- 표현 영역은 사용자의 요청을 해석해서 응용 서비스에 전달하고 응용 서비스의 실행 결과를 사용자가 이해할 수 있는 형식으로 변환하여 응답
- 웹 애플리케이션의 표현 영역은 HTTP 요청을 응용 영역이 필요로 하는 형식으로 변환해서 응용 영역에 전달하고 응용 영역의 응답을 HTTP 응답으로 변환하여 전송
응용 영역

- 기능을 구현하기 위해 도메인 영역의 도메인 모델을 사용
- 응용 서비스는 로직을 직접 수행하기보다는 도메인 모델에 로직 수행을 위임
- 응용 영역은 도메인 모델을 이용해서 사용자에게 제공할 기능을 구현하며 실제 도메인 로직 구현은 도메인 모델에 위임
도메인 영역
인프라스트럭처 영역

- 논리적인 개념을 표현하기보다는 실제 구현을 다룸
- 도메인, 응용, 표현 영역은 구현 기술을 사용한 코드를 직접 개발하지 않으며 인프라스트럭처 영역에서 제공하는 기능을 사용해서 필요한 기능을 개발
계층 구조 아키텍처
- 표현 영역과 응용 영역은 도메인 영역을 사용하고 도메인 영역은 인프라스트럭처 영역을 사용하므로 계층 구조를 적용하기에 적합
- 계층 구조는 그 특성상 상위 계층(고수준)에서 하위 계층(저수준)으로의 의존만 존재하고 하위 계층은 상위 계층에 의존하지 않음
- 계층 구조를 엄격하게 적용한다면 상위 계층은 바로 아래의 계층에만 의존을 가져야 하지만 구현의 편리함을 위해 계층 구조를 유연하게 적용하기도 함
- 예) 애플리케이션 레이어에서 구현 기술을 사용하는 인프라스트럭처의 의존성을 가짐
- 표현, 응용, 도메인 계층이 상세한 구현 기술을 다루는 인프라스트럭처 계층에 종속
DIP
- 고수준 모듈은 의미 있는 단일 기능을 제공하는 모듈
- 저수준 모듈은 하위 기능을 실제로 구현한 것이며 고수준 모듈이 제대로 동작하려면 저수준 모듈을 사용해야 함
- 위의 단점은 구현 변경과 테스트가 어렵다는 문제이며 이를 해결하기 위해 DIP를 사용
- DIP는 저수준 모듈이 인터페이스를 이용하여 고수준 모듈에 의존하도록 변경하는 것
- DIP를 적용할 때 하위 기능을 추상화한 인터페이스는 고수준 모듈 관점에서 도출해야 한다.

- 아키텍처 수준에서 DIP를 적용하면 인프라스트럭처 영역이 응용 영역과 도메인 영역에 의존(상속)하는 구조가 됨

- DIP를 적용하면 응용 영역과 도메인 영역에 영향을 최소화하면서 구현체를 변경하거나 추가 가능
도메인 영역의 주요 구성요소
- 엔티티(Entity)
- 고유의 식별자를 갖는 객체로 자신의 라이프 사이클을 가짐
- 도메인 모델의 데이터를 포함하며 해당 데이터와 관련된 기능을 함께 제공
- 밸류(Value)
- 고유의 식별자를 갖지 않는 객체로 개념적으로 하나인 값을 표현할 때 사용
- 엔티티의 속성으로 사용할 뿐만 아니라 다른 밸류 타입의 속성으로도 사용
- 애그리거트(Aggregate)
- 애그리거트는 연관된 엔티티와 밸류 객체를 개념적으로 하나로 묶은 것
- 리포지토리(Repository)
- 도메인 서비스(Domain Service)
- 특정 엔티티에 속하지 않은 도메인 로직을 제공
- 도메인 로직이 여러 엔티티와 밸류를 필요로 하면 도메인 서비스에서 로직을 구현
애그리거트
- 도메인 모델에서 전체 구조를 이해하는 데 도움이 되는 것
- 관련 객체를 하나로 묶은 군집
- 애그리거트에 속한 객체를 관리하는 루트 엔티티를 가짐
- 루트 엔티티(애그리거트 루트)
- 애그리거트에 속해 있는 엔티티와 밸류 객체를 이용해서 애그리거트가 구현해야 할 기능을 제공
- 애그리거트를 사용하는 코드는 애그리거트 루트가 제공하는 기능을 실행하고 애그리거트 루트를 통해서 간접적으로 애그리거트 내의 다른 엔티티나 밸류 객체에 접근
- 위와 같은 방식으로 애그리거트 단위의 캡슐화가 이루어짐
- 애그리거트의 일관성이 깨지지 않도록 하는 역할
- 애그리거트 내부의 다른 객체를 조합해서 기능을 완성함
- 구성요소의 상태만 참조하는 것이 아니라 기능 실행을 위임하기도 함
- 모델을 잘 이해할 수 있고 애그리거트 단위로 일관성을 관리하기 때문에, 애그리거트는 복잡한 도메인을 단순한 구조로 만듦
- 애그리거트는 관련된 모델을 하나로 모았기 때문에 한 애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 가짐
- 도메인 규칙을 지키려면 애그리거트에 속한 모든 객체가 정상 상태를 가져야 함
- 애그리거트 외부에서 애그리거트에 속한 객체를 직접 변경하면 안 됨
- 한 트랜잭션에서 한 애그리거트만 수정한다는 것은 애그리거트에서 다른 애그리거트를 변경하지 않는다는 것
- 애그리거트는 최대한 서로 독립적으로 설계해야 함
- 애그리거트를 참조한다는 것은 애그리거트의 루트를 참조한다는 것
- ID 참조를 사용하면 모든 객체가 참조로 연결되지 않고 한 애그리거트에 속한 객체들만 참조로 연결
- 애그리거트의 경계를 명확히 하고 애그리거트 간 물리적인 연결을 제거하기 때문에 응집도를 높임
- 애그리거트가 갖고 있는 데이터를 이용해서 다른 애그리거트를 생성해야 한다면 애그리거트에 팩토리 메서드를 구현하는 것을 고려
리포지토리
- 도메인 객체를 지속적으로 사용하려면 물리 저장소에 저장해야 하는데 이 역할을 리포지토리가 함
- 엔티티나 밸류가 요구사항에서 도출되는 도메인 모델이라면 리포지터리는 구현을 위한 도메인 모델
- 애그리거트 단위로 도메인 객체를 저장하고 조회하는 기능을 정의
- 응용 서비스와 리포지터리는 밀접한 연관이 있음
- 응용 서비스는 필요한 도메인 객체를 구하거나 저장할 때 리포지터리를 사용
- 응용 서비스는 트랜잭션을 관리하는데, 트랜잭션 처리는 리포지터리 구현 기술의 영향을 받음
- 리포지터리를 사용하는 주체가 응용 서비스
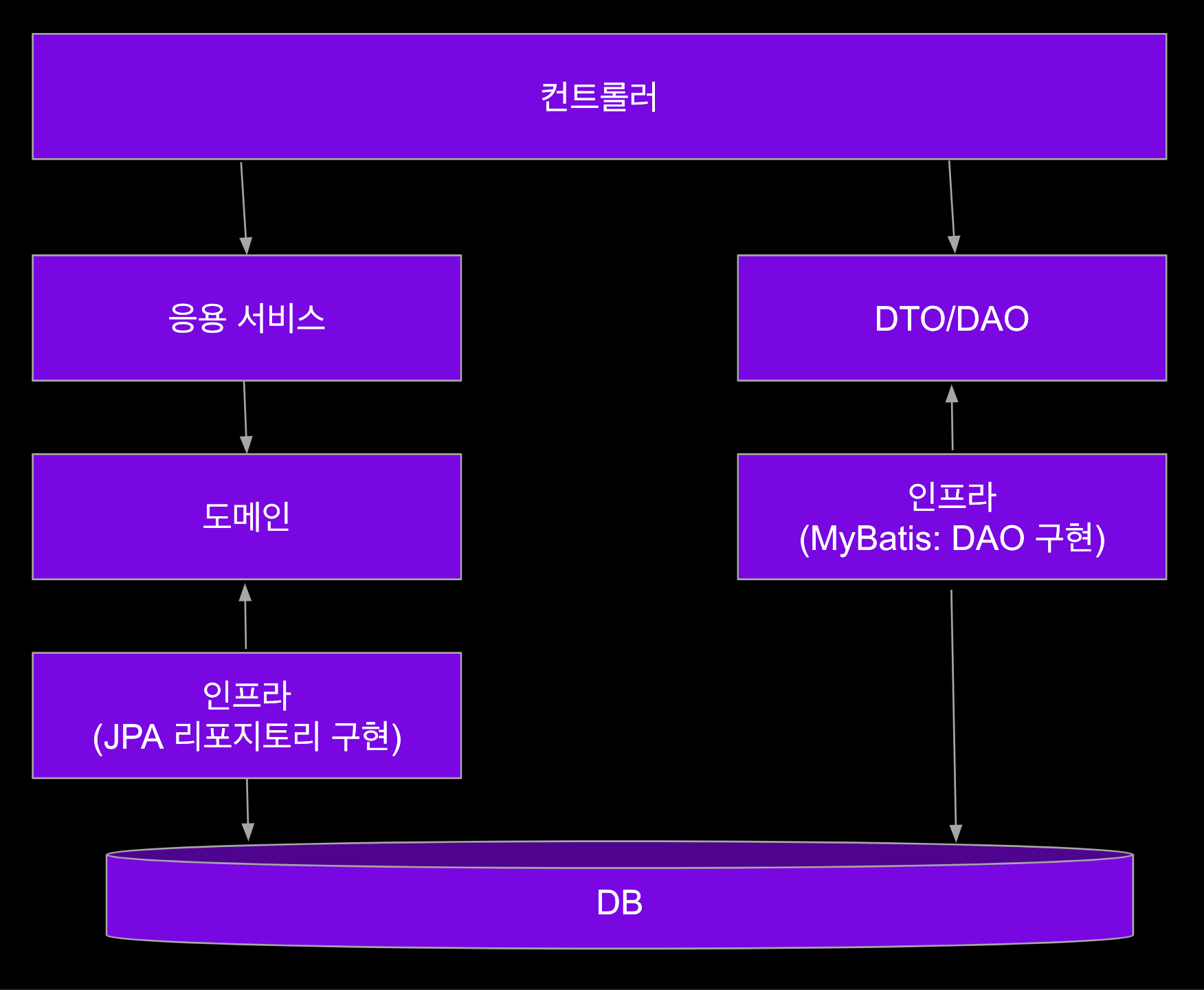
JPA와 모델 구현
- 애그리거트를 수정한 결과를 저장소에 반영하는 메서드를 추가할 필요 없음
- JPA를 사용하면 트랜잭션 범위에서 변경한 데이터를 자동으로 영속화
- 매핑 구현
- 애그리거트 루트는 엔티티이므로 @Entity로 매핑 설정
- 밸류는 @Embeddable로 매핑 설정
- 밸류 타입 프로퍼티는 @Embedded로 매핑 설정
- @AttributeOverride는 정의된 컬럼 이름을 변경할 때 사용
- @Entity와 @Embeddable로 클래스를 매핑하려면 기본 생성자를 제공해야 함
- 밸류 컬렉션을 별도 테이블로 매핑할 때는 @ElementCollection과 @CollectionTable을 함께 사용
- @OrderColumn 애너테이션을 이용해서 지정한 컬럼에 리스트의 인덱스 값을 저장
- @CollectionTable은 밸류를 저장할 테이블을 지정
- @JoinColumn을 이용하여 외부키를 지정
- 식별자를 밸류 타입으로 만들 수도 있으며 @Id가 아닌 @EmbeddedId를 사용하고 기능을 추가할 수 있음
- 애그리거트에서 루트 엔티티를 제외한 나머지 구성요소는 대부분 밸류이며 별도 테이블에 데이터를 저장한다고 엔티티는 아님
- 밸류가 아니라 엔티티가 확실하다면 해당 엔티티가 다른 애그리거트는 아닌지 확인해야 함
- 밸류를 매핑한 테이블을 지정하기 위해 @SecondaryTable과 @AttibuteOverride를 사용
- 계층 구조를 갖는 밸류 타입
- @Embeddable 타입의 클래스 상속 매핑을 지원하지 않음
- @Entity와 @Inheritance 그리고 구현 클래스 구분을 위한 타입 식별 @DiscriminatorColumn을 사용
- 구현하는 쪽은 @Entity, @DiscriminatorValue 사용
- 하이버네이트는 @Embeddable 타입에 대한 컬렉션의 clear() 메서드를 호출 시 컬렉션에 속한 객체를 로딩하지 않고 delete
- JPA 매핑 시 유념해야할 점은 애그리거트에 속한 객체가 모두 모여야 완전한 하나가 된다는 것
- 애그리거트가 완전해야 하는 이유
- 상태를 변경하는 기능을 실행할 때 애그리거트 상태가 완전해야 함 (예: 생성, 삭제)
- 표현 영역에서 조회 전용 기능을 위해 애그리거트의 상태 정보를 보여줄 때 필요
스프링 데이터 JPA를 이용한 조회 기능
- 스펙은 애그러거트가 특정 조건을 충족하는지를 검사할 때 사용하는 인터페이스
- 조회 전용 모델을 만드는 이유는 표현 영역을 통해 사용자에게 데이터를 보여주기 위함
- 동적 인스턴스의 장점은 JPQL을 그대로 사용하므로 객체 기준으로 쿼리를 작성하면서도 동시에 지연/즉시 로딩과 같은 고민 없이 원하는 모습으로 데이터를 조회할 수 있다는 점이다.
- @Subselect는 조회 쿼리를 값으로 가지며 결과를 매핑할 테이블처럼 사용
- 뷰를 수정할 수 없듯이 @Subselect로 조회한 @Entity도 수정 불가
- @Immutable을 사용하면 하이버네이트는 해당 엔티티의 매핑 필드/프로퍼티가 변경되도 DB에 영속화 무시
- @Synchronized는 해당 엔티티와 관련된 테이블 목록을 명시하며 하이버네이트는 엔티티를 로딩하기 전에 지정한 테이블과 관련된 변경이 발생하면 플러시를 먼저 수행
요청 처리 흐름
- 표현 영역
- 사용자가 전송한 데이터 형식이 올바른지 검사
- 응용 서비스의 요구사항에 맞게 데이터를 전달하여 기능 실행을 위임
- 요청을 받은 표현 영역은 URL, 요청 파라미터, 쿠키, 헤더 등을 이용해서 사용자가 실행하고 싶은 기능을 판별하고 그 기능을 제공하는 응용 서비스를 실행
- 사용자가 시스템을 사용할 수 있는 흐름(화면)을 제공하고 제어
- 사용자의 요청을 알맞은 응용 서비스에 전달하고 결과를 사용자에게 제공
- 사용자의 세션을 관리
- 필수 값, 값의 형식, 범위 등을 검증
- 응용 서비스
- 도메인 모델을 이용해서 기능을 구현
- 기능 구현에 필요한 도메인 객체를 리포지토리에서 가져와 실행하거나 신규 도메인 객체를 생성해서 리포지터리에 저장
- 기능을 실행하는 데 필요한 입력 값을 메서드 인자로 받고 실행 결과를 리턴
- 사용자와 상호작용은 표현 영역이 처리하기 때문에 응용 서비스는 표현 영역에 의존하지 않음
- 표현영역과 도메인 영역을 연결해 주는 창구 역할 (Facade)
- 도메인의 상태 변경을 트랜잭션으로 처리
- 도메인 로직을 응용 서비스에서 구현하게 되면 도메인 로직의 응집도가 떨어지고 중복이 될 가능성이 있어 구현하면 안 됨
- 응용 서비스는 표현 영역에서 필요한 데이터만 리턴하는 것이 기능 실행 로직의 응집도를 높이는 확실한 방법
- 파라미터 타입을 결정할 때 주의할 점은 표현 영역과 관련된 타입을 사용하면 안 된다는 것
- 표현 계층과 의존이 발생하여 응용 서비스 단독으로 테스트하기 어려워짐
- 표현 계층의 변경으로 인해 응용 서비스도 변경될 수 있음
- 응용 서비스가 표현 영역의 역할을 대신할 수 있음
- 데이터의 존재 유무와 같은 논리적 오류를 검증
- 응용 서비스가 사용자 요청 기능을 실행하는 데 별다른 기여를 하지 못한다면 굳이 서비스를 만들지 않아도 됨

도메인 서비스
- 도메인 영역에 위치한 도메인 로직을 표현할 때 사용 (예: 계산 로직, 외부 시스템 연동)
- 도메인 영역의 애그리거트나 밸류와 같은 구성 요소와 도메인 서비스를 비교할 때 다른 점은 도메인 서비스는 상태 없이 로직만 구현
- 도메인 서비스를 도메인 객체에 주입하면 의존성이 높아지므로 하지 않는다.
- 도메인 로직을 수행하지 응용 로직을 수행하지 않음
- 도메인 서비스는 도메인 패키지에 위치
애그리거트 트랜잭션 관리
- 선점 잠금(Pessimistic Lock)
- 먼저 애그리거트를 구한 스레드가 애그리거트 사용이 끝날 때까지 다른 스레드가 해당 애그리거트를 수정하지 못하게 막는 방식
- 보통 DMBS가 제공하는 행단위 잠금을 사용해서 구현
- 스프링 데이터 JPA는 @Lock 애너테이션을 사용해서 잠금 모드를 지정
- 선점 잠금 기능을 사용할 때는 잠금 순서에 따른 교착 상태가 발생하지 않도록 주의해야 함
- 선점 잠금에 따른 교착 상태는 상대적으로 사용자 수가 많을 때 발생할 가능성이 높고, 사용자 수가 많아지면 교착 상태에 빠지는 스레드는 더 빠르게 증가
- @QueryHints를 이용하여 잠금을 구할 때 최대 대기 시간을 지정
- 비선점 잠금(Optimistic Lock)
- 동시에 접근하는 것을 막는 대신 변경한 데이터를 실제 DBMS에 반영하는 시점에 변경 가능 여부를 확인하는 방식
- 비선점 잠금을 구현하려면 애그리거트에 버전으로 사용할 숫자 타입 프로퍼티를 추가해야 함
- JPA는 @Version을 붙이고 매핑되는 테이블에 버전을 저장할 컬럼을 추가하면 됨
- JPA는 엔티티가 변경되어 UPDATE 쿼리를 실행할 때 @Version에 명시한 필드를 이용해서 비선점 잠금 쿼리를 실행
- 응용 서비스에 전달할 요청 데이터는 사용자가 전송한 버전 값을 포함하며 애그리거트 버전과 일치할 경우 기능을 수행
- VersionConflictException은 이미 누군가가 애그리거트를 수정했다는 것을 의미
- OptimisticLockingFailureException은 누군가가 거의 동시에 애그리거트를 수정했다는 것을 의미
- 애그리거트 내에 어떤 구성요소의 상태가 바뀌면 루트 애그리거트의 버전 값이 증가해야 비선점 잠금이 올바르게 동작함
- 오프라인 선점 잠금
- 단일 트랜잭션에서 동시 변경을 막는 선점 잠금 방식과 달리 오프라인 선점 잠금은 여러 트랜잭션에 걸쳐 동시 변경을 막음
- 오프라인 선점 잠금은 크게 잠금 선점 시도, 잠금 확인, 잠금 해제, 잠금 유효시간 연장의 네가지 기능이 필요
도메인 모델과 바운디드 컨텍스트
- 모델은 특정한 컨텍스트 하에서 완전한 의미를 가짐
- 구분되는 경계를 갖는 컨텍스트를 바운디드 컨텍스트라고 부름
- 바운디드 컨텍스트
- 모델의 경계를 결정하며 한 개의 바운디드 컨텍스트는 논리적으로 한 개의 모델을 가짐
- 바운디드 컨텍스트는 용어를 기준으로 구분
- 바운디드 컨텍스트는 실제로 사용자에게 기능을 제공하는 물리적 시스템으로 도메인 모델은 이 바운디드 컨텍스트 안에서 도메인을 구현
- 조직 구조에 따라 바운디드 컨텍스트가 결정됨

- 여러 하위 도메인을 하나의 바운디드 컨텍스트에서 개발할 때 주의할 점은 하위 도메인의 모델이 섞이지 않도록 하는 것
- 한 개의 바운디드 컨텍스트가 여러 하위 도메인을 포함하더라도 하위 도메인마다 구분되는 패키지를 갖도록 구현해야 하며, 이렇게 함으로써 하위 도메인을 위한 모델이 서로 뒤섞이지 않고 하위 도메인마다 바운디드 컨텍스트를 갖는 효과를 낼 수 있음
- 바운디드 컨텍스트는 도메인 기능을 사용자에게 제공하는 데 필요한 표현, 응용, 인프라 영역 그리고 DB 테이블 스키마까지 포함됨
- 바운디드 컨텍스트가 반드시 사용자에게 보여지는 UI(표현)를 가지고 있어야 하는 것은 아님
- 바운디드 컨텍스트 간 관계
- 상류 컴포넌트는 일종의 서비스 공급자 역할을 하며 하류 컴포넌트는 그 서비스를 사용하는 고객 역할
- 상류 팀과 하류 팀은 개발 계획을 서로 공유하고 일정을 협의해야 함
- 상류 컴포넌트는 보통 하류 컴포넌트가 사용할 수 있는 통신 프로토콜을 정의하고 이를 공개 (공개 호스트 서비스)
- 상류 컴포넌트의 서비스는 상류 바운디드 컨텍스트의 도메인 모델을 따름
- 하류 컴포넌트는 상류 서비스의 모델이 자신의 도메인 모델에 영향을 주지 않도록 보호해 주는 완충지대(안티코럽션 계층)가 필요
- 상류와 하류가 공유하는 모델을 공유 커널이라고 하며 중복을 줄여주는 것이 장점
- 독립 방식 관계는 서로 통합하지 않는 방식
- 컨텍스트 맵

이벤트
- 이벤트는 과거에 벌어진 어떤 것을 의미
- 이벤트가 발생했다는 것은 상태가 변경됐다는 것이고 그에 반응하여 원하는 동작을 수행해야 함
- 도메인 모델에 이벤트를 도입하려면 이벤트, 이벤트 생성 주체, 이벤트 디스패처(퍼블리셔), 이벤트 핸들러(구독자)를 구현해야 함

- 도메인 모델에서 이벤트 생성 주체는 엔티티, 밸류, 도메인 서비스와 같은 도메인 객체
- 이벤트 핸들러는 이벤트 생성 주체가 발생한 이벤트에 반응
- 이벤트 생성 주체와 이벤트 핸들러를 연결해 주는 것이 이벤트 디스패처
- 이벤트의 구성: 종류(클래스 이름), 발생 시간, 추가 데이터(예: 주문번호, 신규 배송지 정보 등)
- 이벤트 이름은 과거 시제를 사용
- 이벤트 용도는 트리거와 서로 다른 시스템 간의 데이터 동기화
- 이벤트를 사용하면 서로 다른 도메인 로직이 섞이는 것을 방지
- 이벤트 자체를 위한 상위 타입은 존재하지 않음
- 도메인 상태 변경과 이벤트 핸들러는 같은 트랜잭션 범위에서 실행됨
- 이벤트를 처리하는 방식
- 로컬 핸들러를 비동기로 실행하기
- 메시지 큐를 사용하기
- 이벤트 저장소와 이벤트 포워더 사용하기
- 이벤트 저장소와 이벤트 제공 API 사용하기
- 이벤트 저장소를 이용할 때 API 방식은 외부 핸들러가 API 서버를 통해 이벤트 목록을 가져가고, 포워더 방식은 포워더를 이용해서 이벤트를 외부에 전달하는 것에서 차이가 있음
- 이벤트 적용 시 추가 고려 사항
- 이벤트 소스를 EventEntry에 추가할지 여부
- 포워더를 구현할 때는 실패한 이벤트의 재전송 횟수 제한을 두어야 함
- 이벤트 손실에 대해서 고려
- 이벤트 순서에 대해서 고려
- 이벤트 재처리에 대한 고려
- 이벤트를 비동기로 처리할 때 DB 트랜잭션을 고려해야 하며 트랜잭션이 성공할 때만 이벤트 핸들러를 실행하는 것이 안전함
CQRS
- 시스템이 제공하는 기능은 크게 상태를 변경하는 것과 상태 정보를 조회하는 기능 두 가지로 나눌 수 있음
- 상태를 변경하는 범위와 상태를 조회하는 범위가 정확하게 일치하지 않기 때문에 단일 모델로 두 종류의 기능을 구현하면 모델이 불필요하게 복잡해짐
- CQRS는 명령을 위한 모델과 상태를 제공하는 조회를 위한 모델을 분리하는 패턴
- 명령 모델과 조회 모델은 서로 다른 기술을 이용해서 구현할 수 있음
- 명령 모델은 트랜잭션을 지원하는 RDBMS를 사용하고, 조회 모델은 조회 성능이 좋은 메모리 기반 NoSQL을 사용할 수 있음
- 두 데이터 저장소 간 동기화는 이벤트로 처리
- 명령 모델에서 데이터가 바뀌면 동기 이벤트와 글로벌 트랜잭션을 사용해서 실시간 동기화가 가능하지만 응답속도와 처리량이 떨어지는 단점이 있음
- 서로 다른 저장소의 데이터를 특정 시간 안에만 동기화해도 된다면 비동기로 데이터를 전송
- 장점
- 명령 모델을 구현할 때 도메인 자체에 집중할 수 있음
- 조회 성능을 향상시킬 수 있음
- 단점
- 구현해야 할 코드가 많아짐
- 더 많은 구현 기술이 필요